2025年10月26日至30日,第44届国际计算机辅助设计会议(International Conference on Computer-Aided Design,ICCAD 2025)在德国慕尼黑隆重举行。这是自1982年ICCAD创办以来首次在美国之外举办。ICCAD由IEEE与ACM联合主办,是电子设计自动化(EDA)领域历史最悠久、影响力最广泛的国际顶级学术会议之一,长期引领全球集成电路设计与EDA技术的发展方向。同时,ICCAD是中国计算机学会(CCF)推荐的计算机体系结构与高性能计算方向顶级国际学术会议,2025年文章投稿量逾千篇,接收率为24.7%
在本届ICCAD上,北京欧美大片ppt免费大全集成电路学院共有 8篇高水平学术论文入选,充分体现了我院在新型计算架构、AI驱动EDA算法与智能电路设计等方向的持续创新与国际影响力。入选论文覆盖存算一体架构优化、低精度感知训练算法、混合RAM异构加速器设计、高维模拟电路自动化优化、良率建模与优化、以及物理数据融合非理想建模 等多个前沿研究领域,展示了我院在“从器件—电路—架构—算法”全栈协同设计方面的系统研究优势。8篇论文成果简介如下:
论文1:
HRAMTran: A Hybrid-RAM Transformer Accelerator With Dynamic Sparsity Floating-Point CIM and Written-Back Transpose Array
作者:Bojun Zhang, Jinkai Wang, Xianan Zhu, Ziyuan Guo, Zhengkun Gu, Kaili Zhang,
Zhizhong Zhang, Kun Zhang, Weisheng Zhao, Yue Zhang
近年来,Transformer模型在众多领域展现出了卓越性能,但其注意力机制涉及大量矩阵乘法计算与存储访问,能耗和延迟过高,制约了其在边缘端部署。在此背景下,本文提出了HRAMTran存算一体加速器,通过“电路—架构—系统”协同优化实现高效推理。电路层面提出指数位驱动的动态稀疏机制与尾数复用MAC方案,有效减少低影响的操作数计算,并提升并行度。架构层面采用SOT-MRAM与SRAM混合RAM异构集成设计,兼顾能耗与访问速度,同时提出按列多比特写入的转置SRAM阵列,将K矩阵转置写回周期由256次降至16次。系统层面通过跨Token流水线设计显著提升计算核利用率和吞吐率。在28nm工艺下,HRAMTran实现了68.77TFLOPS/W、3.6μJ/Token,且对WMT14数据集的推理能耗下降1.8倍,精度损失小于0.2%,整体性能均优于现有方案。
2023级博士生张伯均为该论文的第一作者,北航集成电路学院张悦教授和杭州北航国新院王进凯副研究员为共同通讯作者,北京欧美大片ppt免费大全为第一完成单位。该研究工作获得了国自然等项目的支持。

(a)指数位驱动的浮点数动态稀疏机制,(b)混合RAM存算一体架构,(c)SRAM位线转置阵列结构,(d)HRAMTran系统,(e)后仿版图布局
论文2:
DIVE: Dynamic Information-Guided Variable Expansion for Deeper Analog Circuit Optimization
作者:Zhuohua Liu, Weilun Xie, Yuxuan Zhang, Chen Wang, Yuanqi Hu, Wei W. Xing
随着现代模拟与混合信号(AMS)电路的复杂度日益提升,其核心的晶体管尺寸优化面临着严峻挑战,设计者必须在由数十个参数构成的庞大空间中探索,但每一次电路仿真都极为耗时。为此,以贝叶斯优化(BO)为代表的自动化方法被提出,作为提升设计效率的解决方案。虽然,BO因其样本高效性而备受关注,但在处理高维参数空间时其性能会急剧下降,也即“维度灾难”,其代理模型难以精确学习,导致优化停滞。此外,其他主流方法也存在样本需求量大(强化学习)或过度简化电路特性(嵌入方法)的问题,难以在仿真效率、优化深度和方法普适性上取得最佳平衡。为解决以上问题,本研究提出了DIVE:一种动态信息化变量扩展优化框架。该框架包含约束感知加权互信息分析、自适应维度扩展机制和互信息引导的核函数学习三方面创新,从参数评估、空间管理到模型学习层级开展协同优化。在多个基准电路上,DIVE展现了卓越的性能,实现了高达21.11倍的仿真效率提升和2.69倍的电路性能改进,同时该框架通过动态聚焦于高信息量参数,成功探索到了传统方法难以触及的更优设计空间,为解决高维“黑盒”优化问题开辟了新路径。
2025级博士生刘卓铧为该论文的第一作者,北航集成电路学院胡远奇教授和谢菲尔德大学邢炜讲师为共同通讯作者,北京欧美大片ppt免费大全为第一完成单位。该研究工作获得了国自然等项目的支持。
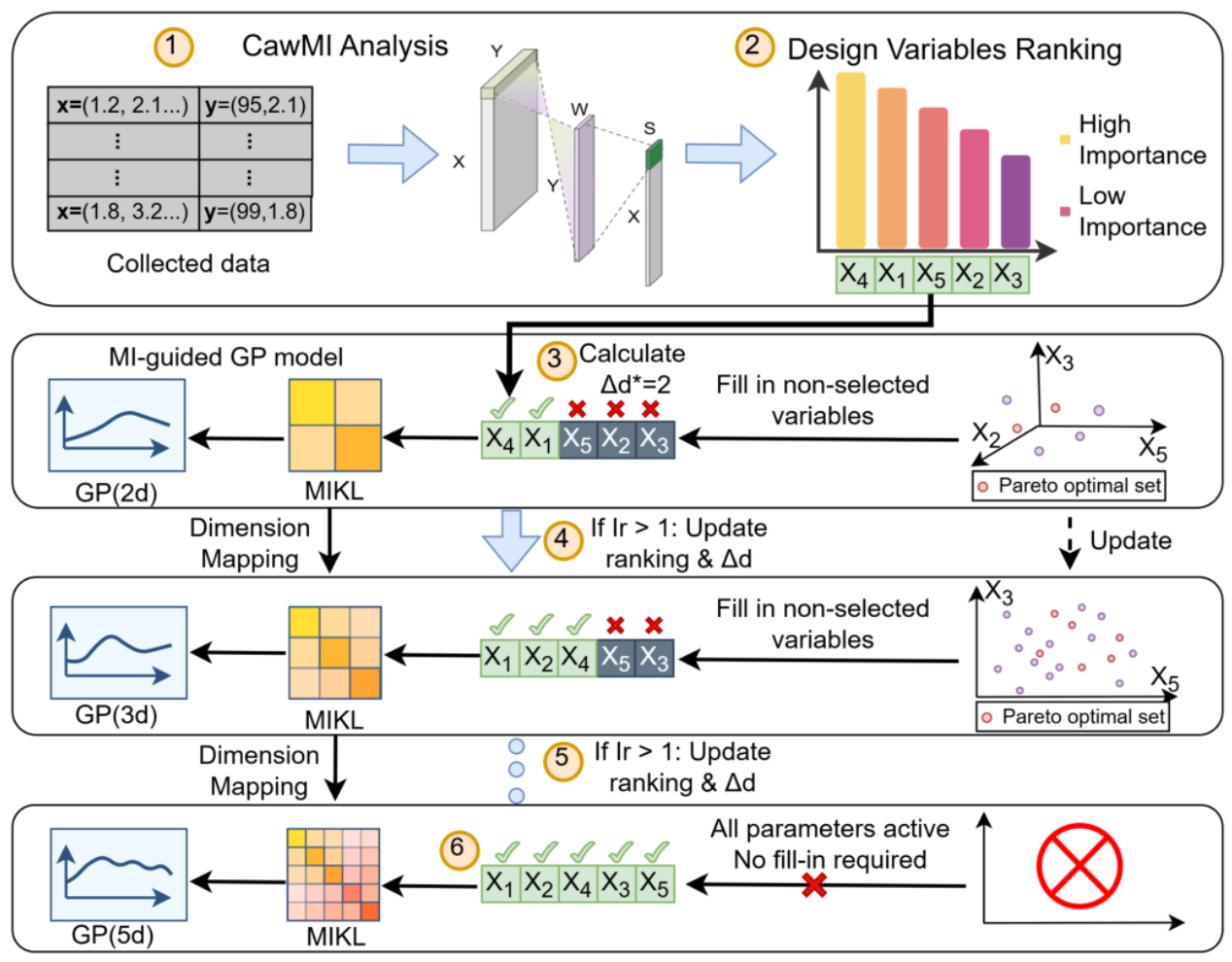
DIVE框架系统框图
论文3:
CorDBA: Corners Decoupled Bayesian Approach for yield optimization
作者:Yue Zhang, Yunqi Li, Shichang Ye, Bojun Zhang, Jinkai Wang, Zhizhong Zhang, Peng Wang
有限的资源和⾼昂的模拟成本之间的⽭盾,是先进节点电路设计中良率优化的核⼼挑战。本⽂提出了⼀种名为 CorDBA 的新框架,通过引⼊⼀种新颖的⻆提取⽅法,利⽤⼯艺随机性 的统计⻆信息,将良率优化过程与⾼成本的良率估计过程解耦。具体⽽⾔,参数优化过程在 ⼀组固定统计⻆下进⾏ max-minimum 优化,⽽电路是否满⾜良率要求则通过⽬标良率分位 数提取的统计⻆进⾏独⽴评估,这种解耦机制将原本乘法级的仿真复杂度降低⾄加法级。此外,CorDBA ⽀持多阶段渐进式优化,允许低良率阶段的优化信息被后续更⾼良率⽬标的优化过程复⽤。我们在模拟、数字及采⽤新型器件的多种电路上验证了该框架的有效性。实验结果表明,与当前最先进的⽅法相⽐,CorDBA 在 SPICE 模拟速度上实现了 3.6 倍的提升,并在稳健性⽅⾯(以标准差衡量)取得了⾼达 134.7 倍的显著改善。
2021 级博⼠⽣张越为该论⽂第⼀作者,北航集成电路学院王鹏教授和张志仲副教授为 共同通讯作者,北京欧美大片ppt免费大全为第一完成单位,该项⽬取得了国家重点研发计划等项⽬的⽀持。
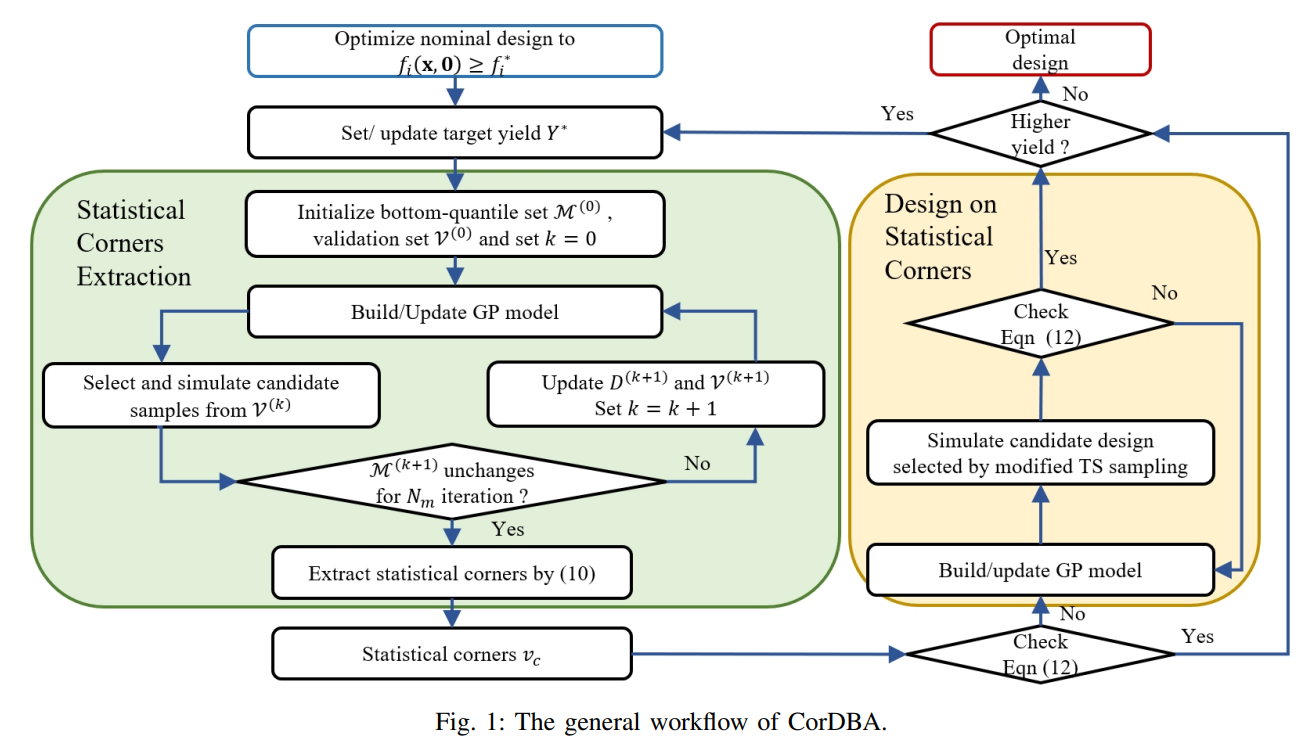
论文4:
An Adaptive Sparse Matrix Compression CIM Accelerator based on 256Kb SOT-MRAM for Downlink Massive MIMO Communications
作者:Liangchen Li, Jianxin Wu, Changyu Li, Liang Zhang, Anyang Yu, Junda Zhao,
Zhaohao Wang, Chengyuan Sun, Kaihua Cao, Hongxi Liu, Wang Kang, He Zhang, Weisheng Zhao
大规模MIMO下行预编码涉及高维稀疏矩阵运算,对存储与计算架构带来挑战。本文提出MAMS-CIM,一种基于256Kb SOT-MRAM的自适应压缩CIM加速器。其创新点包括:多稀疏模式块压缩策略实现dense/sparse/全零子块全覆盖;自适应映射匹配机制解决压缩存储后的对齐与功耗问题;基于高斯算法的复数乘法单元与复用控制器提升精度与效率。实验证明,在32×256×8 MIMO任务中,该方案在信噪比20dB时可将SER降至0.1%,并实现1.35×–8.35×存储压缩、最高39.4×能耗节省和9.85×加速,能效与吞吐率均优于现有方案。
2023级硕士生李良宸为该论文的第一作者,北航集成电路学院张和副教授和康旺教授为共同通讯作者,北京欧美大片ppt免费大全为第一完成单位。该研究工作获得了国家重点研发计划等项目的支持。
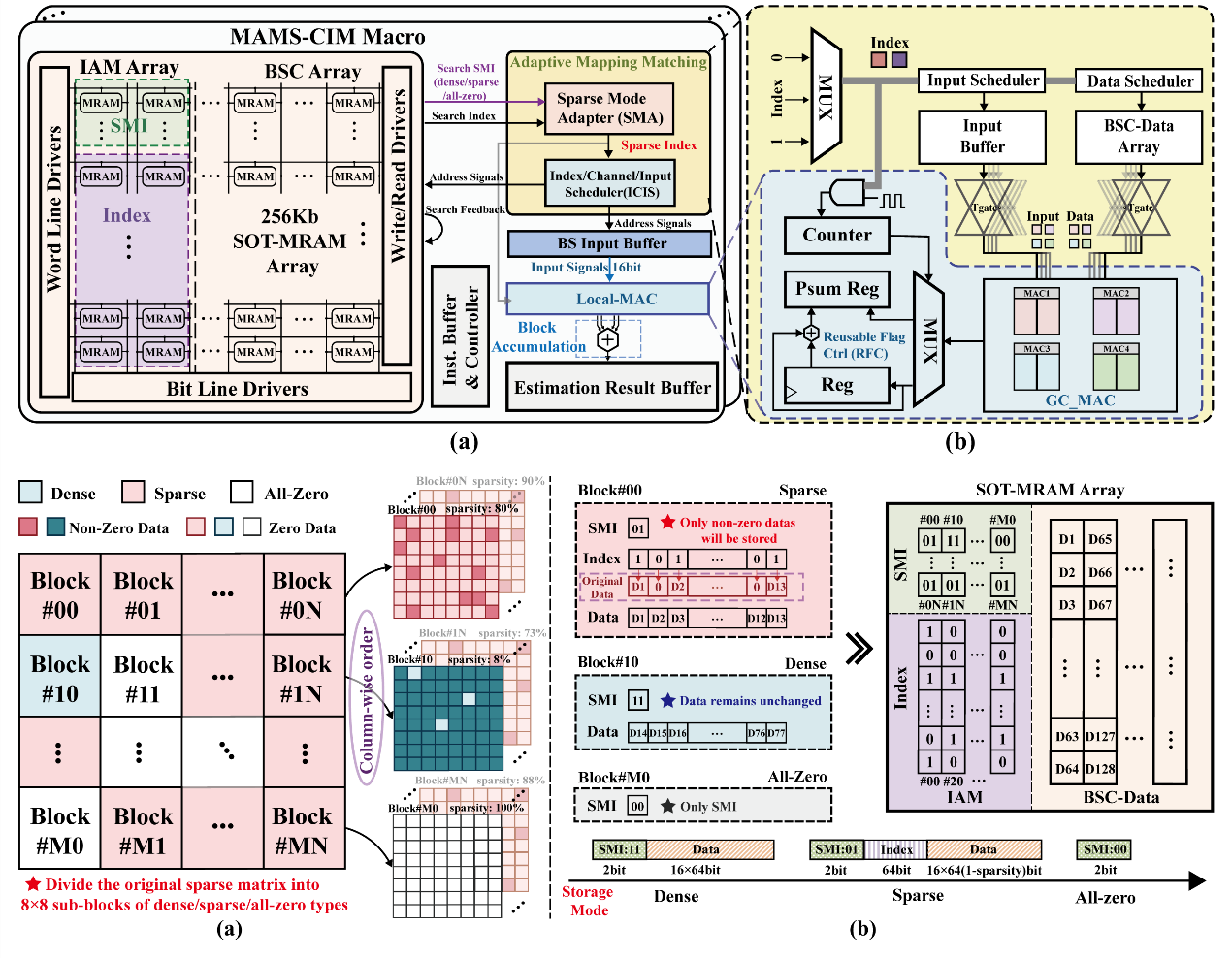
论文5:
Towards Accurate Characterization of In-Memory Computing Non-Idealities: A Physics & Data Co-Driven Generative Framework
作者:Jing Kou, Guangyao Wang, Saiya Wang, Yuexi Lv, Liang Zhang, Chenglin Yu, Xinghao Cui, Yulong Liu, Wei. W Xing, Wang Kang
存内计算IMC芯片广受器件非线性、线阻、编程误差和噪声等非理想效应影响,严重制约精度和应用落地。本文提出PDGM-IMC,首个物理与数据协同驱动的生成式建模框架。方法基于归一化流模型,在生成器中嵌入物理驱动层,显式模拟器件与电路非理想性,同时结合条件仿射耦合层对实测数据进行学习,捕捉空间相关性和芯片间差异。该框架不仅具备可解释性,还能显式估计概率密度,支持后续误差补偿优化。在40nm eFlash IMC SoC上测试表明,建模精度相较现有方法提升最高4.6倍,并显著优于高斯与纯数据驱动模型。
2024级博士生寇竞和2023级博士生王光燿为该论文的共同第一作者,北航集成电路学院康旺教授和英国谢菲尔德大学邢炜助理教授为共同通讯作者,北京欧美大片ppt免费大全为第一完成单位。该研究工作获得了浙江省科技计划等项目的支持。
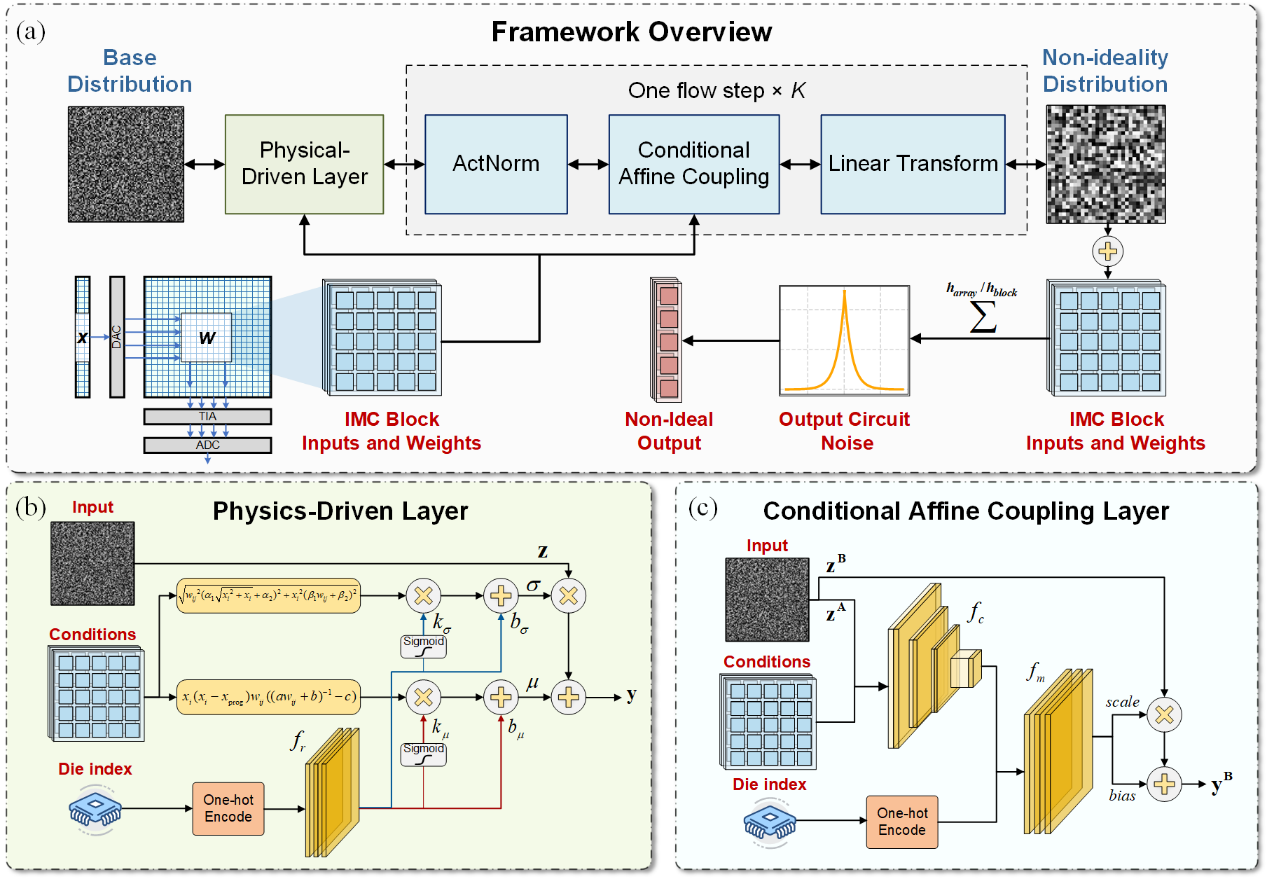
论文6:
BARQ: Boundary-Aware Regularized Training for Accurate Inference on Computing-in-Memory Accelerators with Low-Precision A/D Conversion
作者:Tingrui Ren, Bi Wang, Liang Wang, Yuanfu Zhao
在人工智能推理加速领域,交叉阵列外围模数转换器(A/DC)的面积与功耗开销是存算一体(CIM)芯片的性能瓶颈。所提出的边界感知正则化量化(Boundary-Aware Regularized Quantization,BARQ)首次实现了不改动硬件、仅靠训练算法就将低位宽 A/DC 的成本优势转化为系统能效。BARQ 的核心创新在于把 A/DC 位宽边界形式化为对权重的 ℓ1 范数约束,在训练阶段主动抑制溢出截断并自然诱导非结构化稀疏,同时引入欧氏投影权重初始化,显著减少初始量化误差并加速模型收敛。实验数据显示,在 W/A=4/4 且仅 3 比特 ADC 的条件下,ImageNet/ResNet-50 精度仍达 75.54%(较全精度仅降低 0.59%),CIFAR-100/VGG-11 精度仅下降 1.33%;动态能耗降低 73%,硬件效能最高提升 3.79 倍。这一成果表明,BARQ 能够在保障推理准确率的同时显著提升 CIM 系统的能源效率与可部署性,为下一代低功耗、高性能的人工智能芯片提供了全新解决方案。
2023级博士生任庭瑞为该论文第一作者,北航集成电路学院王碧副教授为论文通讯作者,北京欧美大片ppt免费大全为第一完成单位,该项目取得了国家自然科学基金等项目的支持。
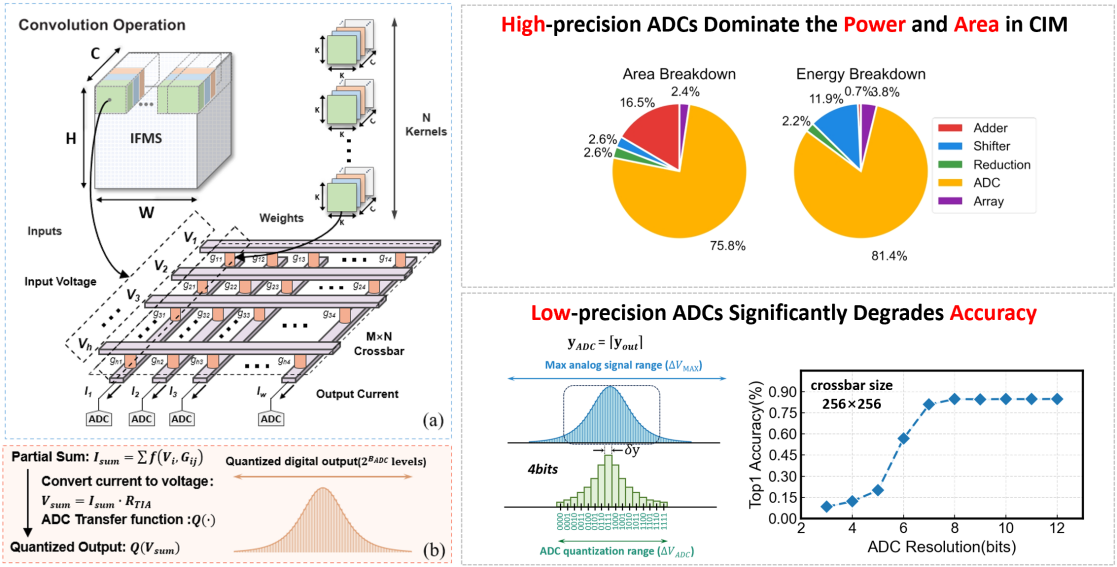
论文7:
PAR-CIM: A Precise Approximate Reconfigurable Digital CIM Macro with 0.35-4b Fractional Mixed-Bitwidth Quantization
作者:Han Zhang, Zhenyu Xue, Wente Yi, Tianshuo Bai, Lehao Tan, Jingcheng Gu, Weijie Ding, Wang Kang, and Biao Pan
随着深度神经网络等人工智能技术的发展,各类网络模型被部署在AI终端中以实现复杂应用。然而,传统AI终端采用存储与计算分离的冯诺伊曼架构设计,这在DNN计算过程中造成了大量的数据搬运开销,也即“存储墙”挑战。为此,数字存算一体(DCIM)架构被提出,作为一种加速DNN计算的解决方案。虽然,DCIM将乘累加操作集成到存储单元中,大幅提升了计算能效,并通过数字逻辑计算提供了更高的计算精度和更强的鲁棒性,但其内部包含占用大量面积和功耗的乘法器阵列与加法器树,导致了显著的硬件资源开销。此外,作为一种定制电路(ASIC),DCIM还存在灵活性不足的问题,难以支持多模型、多算子的应用。因此,新一代DCIM设计需要在硬件资源开销、计算能效和架构灵活性方面寻求最佳平衡。
为解决以上问题,本研究提出了PAR-CIM:一种融合精确与近似计算的高能效可重构存算一体宏单元,包含层级/逻辑门级近似加法器树、分数比特混合精度量化、可重构架构三方面创新,从电路、算法和架构层级开展协同优化。在40nm工艺下,PAR-CIM实现了高达3048 TOPS/W(1b/1b)和7.32 TOPS/mm2(1b/1b)的性能,同时量化算法可在精度损失低于0.74%的情况下将ResNet18、V-FuseMBA(新型Mamba网络)压缩86.61%以上,未来在大模型的软硬件协同加速上存在极大的可扩展性。
2024级硕士生张涵、2024级博士生薛震宇为该论文的共同第一作者,北航集成电路学院潘彪副教授为唯一通讯作者,北京欧美大片ppt免费大全为第一单位,该工作获得国家重点研发计划等项目的支持。
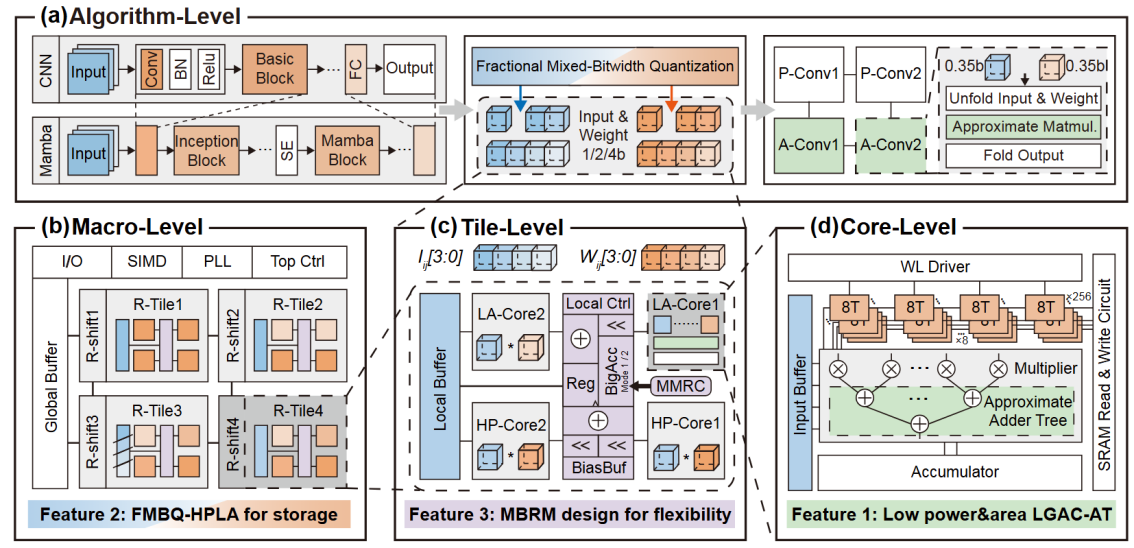
PAR-CIM系统框图
论文8:
Ultra Energy-Efficient Butterfly Counting in Bipartite Networks via Algorithm-Architecture Co-Optimization
作者:Haiyang Liu, Xueyan Wang, Jianlei Yang, Xiaotao Jia, Gang Qu, and Weisheng Zhao
蝶形计数(Butterfly Counting)问题旨在统计图结构中蝶形的数量,是图计算领域的基础问题。现有的蝶形计数算法需重复遍历图中的大量顶点,且由于大规模图数据的可复用性极低,蝶形计数算法存在着显著的高延迟与高能耗问题。为解决以上问题,本研究提出了一种软硬件协同优化的蝶形计数方法。其核心创新在于:一种可支持高度并行与流水线处理的轻量级算法;可提升稀疏数据处理效率的数据压缩与剪枝策略;将软件算法上的优化与FPGA硬件架构无缝集成,大幅提升了整体计算效率。实验结果表明,与基于CPU(512 GB DRAM)和 CPU+GPU(128 GB DRAM)的方法相比,在仅使用 4 GB DRAM的情况下,分别实现了15.84倍和1.35倍的性能提升;同时,其能效达到了CPU+GPU方案的50.14倍,为高能效社区分析与推荐系统提供了可行优化方案。
2022级硕士生刘海阳为该论文的第一作者,北航集成电路学院王雪岩副教授为通讯作者,北京欧美大片ppt免费大全为第一单位,该工作获得国家自然科学基金面上等项目的支持。
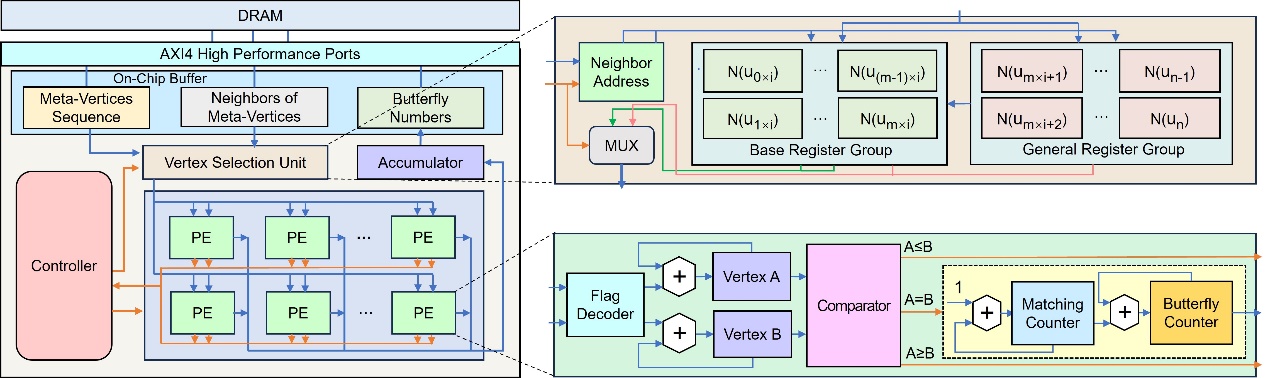
高能效蝶形计数计算架构





